

아마존 클라우드 | AWS Essential 8강 동시성 있는 구현
본문
※ 영상을 선명하게 보기 안내
- 유튜브 영상에서 오른쪽하단에 톱니바퀴를 클릭합니다.
- 팝업목록에서 "품질" 선택하세요.
- 원하는 해상도를 선택해주세요.
※ 모바일에서 Wifi가 아니라면 데이타가 소진될 수 있으니 주의바랍니다.
아마존 클라우드님의 AWS 클라우드강의 청각장애인을 위한 자막
이번 시간에는 aws 동시성 혹은 병렬 성이 있는 구성에 대해서
알아보겠습니다.
첫번째로 빅데이터 서비스를 통한 동시성 있는 구성 그리고 두번째로 분석
서비스를 통한 동시성 혹은 병렬 성 있는 설계의
그 다음에 모바일 서비스 중에서 동시성 있는 서비스 혹은 병렬 성 있는
서비스를 어떻게 설계를 해야 되는지에 대해서 말씀드리도록 하겠습니다.
4 aws 빅데이터 서비스
그중에서 가장 많이 대중적이고 많이 알려진 게 플라스틱 믿을수 라는
서비스 인데요
알약 등 맨 밑에 쓰는 맨 믿을수 6 기반으로
대량의 데이터를 쉽고 빠르며 그리고 비용 효율적으로 처리할 수 있게끔
해주는 웹서비스입니다.
그래서 특히 이제 aws 에서 빅데이터 처리를 간소화 함으로써 동쪽으로
확장할 수 있는 20t 인스턴스 컴퓨팅 자원 이라고 말씀드릴 수가
있는데요 이 시트 인스턴스 에 대해서 대량의 데이터를 쉽고 빠르고 그리고
비용 효율적 으로 배포하고 처리할 수 있도록 지원하는 관리형 하드
프레임워크 라고 말씀드릴 수 있습니다.
4 기본적인 데이터 흐름에 대해서 말씀드리도록 하겠습니다.
우선 뭐 하두 혹은 뭐 스파크 여러가지 의 2집 빅데이터 분석 시스템이
있는데요
기본적인 데이터 흐름에 대해서 먼저 말씀을 드리며 는 첫번째로 데이터를
수집을 해야 되는 거구요
수집한 다음에는 통합을 해야 되는 거구요
통합 이라고 하는것은 저장을 한다.거나 혹은 뭐 데이터베이스의 넣는다거나
하는 작업들을 말씀드리는 겁니다
그 다음에 지금 싸이 있는 데이터를 가지고 실제 정보로 활용을 해야
되는데 정보로 가기 위해 가공을 해야 되는 부분
세번째 부분이 있구요. 그 마지막 부분이 실제로 마케팅이 있나
혹은 다음 디즈니 쓰리 위한 뭐 서비스의 다음 비즈니스 확장을 위한 그런
화 활용도 결과 깝 으로 뽑아낼 수 있다라고 볼 수 있습니다.
그래서 실제로 수집과 같은 경우는 뭐 온 프라미스 있는 데이터 센터 혹은
로컬에 있는 데이터 센터 혹은 지금 구성 하신 시스템에서 직접 다 하셔야
되는 거고요
그 데이터를 모아서 추세로 스토리지 라던가 데이터베이스의 통합 을
하시고요
그 다음에 실제로 이제 분석하는 빅데이터 넌 뭐 클러스터 를 통해서
가공을 할 수 있는 깨 1나 슴에 및 을 쓰다 라고 말씀드릴 수가
있습니다.
그래서 1 라스팅 맵리듀스 에 구성 요소에 대해서 간략하게 4가지
정도 말씀드리도록 하겠습니다.
첫번째 이제 aws 에서 1나 스틱 맨 밑 유쓰 에는 클러스터 라고 존
쟁을 하 존재하는데 클러스터 라는 고 말씀 드리는 것은 실제로 저희가
인스턴스 들에 집합
그래서 가상 컴퓨팅 분석 환경 이라고 보시면 됩니다. 그래서 기본적인 e2
의 집합 이라고 보시면 될거 같고 그 위에 플랫폼 하드 클러스터 같은
것들이 aws 에서 5 관리해주고 설치해주고 운영 해주는 그런 클러스터
라고 보시면 될 것 같습니다.
두번째로 소프트웨어 구성 실제로 1나 스틱맨 및 유스 는 하드 뿐만이
아니 로 뿐만이 아니고 뭐 스파크 라던가 혹은 다른 기타 1
플랫폼 들을 지원을 하고 있으며 그런 분석 ng 를 구성을 하는 하나의
템플릿이 라고 볼 수 있습니다. 그래서 여러가지 소프트웨어를 사용자
여러분들의 원하는 대로 골라서 쓰실 수가 있습니다.
세번째 하드웨어 설정 예를 들면 은 이제 클러스터를 구성을 하고 이제
소프트웨어 어떤 소프트웨어를 쓰겠다
스파크를 쓰겠다 라고 결정을 했는데 그러면 은 그 안에서 내가 실제로
클러스터 사이트에 대한 부분이라고 보시면 될 것 같습니다. 그래서 분석을
위한 컴퓨팅 자원의 갯수 및 용량 이라고
설정을 하는데요 이게 하드웨어 설정이고 요
포함 및 접근에 대해서는 특히 aws 에서는 뭐 다양한 it 인프라
리소스를 사용할 수가 있기 때문에 1나 스틱맨 미드 스 와 연결되어 다른
리소스 들 특히 저장공간 s3 라던가 혹은 또 다른 aws 리소스 를
활용해서 이것들을 주고받고 할 수가 있기 때문에
그럼 구성할 분서 구성할 분석 리소스의 필요한 접근 역할 및 접근을 위한
보안적인 키 라고 말씀드릴 수 있습니다.
그래서 여러분들이 1나 스틱맨 민 쥬스를 구성을 하시고 이런 클러스터
소프트웨어 하드웨어를 구성을 하신다음에 추의 접근을 하셔서 뭐 하드 파일
시스템에서 뭔가 내가 직접 뭘 해야 되겠다 라고 했을 때는 실제로 보안
및 접근해서 엑세스를 열어줘야 되는거구요 그 엑세스 뿐만이 아니고
보안적인 키까지 관리를 하면서 여러분들의 데이터를 안정적으로 관리를 하실
수가 있습니다.
기본적인 aws em 알에 대한 구성에 대해서는 앞에서 알아봤는데요
실제로 맨밑 유스 에 대해서 aws 에서는 아까 말씀드렸던 것처럼
소프트웨어 구성 에서 하도 뿐만이 아니고 스파크 혹은 다른 분석 플랫폼
죄를 제공을 하고 있구요.
그래서 그런 빅데이터 프레 목 중에서도 젤 유명한 하 독 맥 및 유스 f
석 방법에 대해서 간략하게 말씀 드리도록 하겠습니다.
실제로 여러분들이 많이 아시겠지만 제목 거라는 것과
one 듀스 맥 네이비 있구요.
이쪽이 이쪽 워커 들이 맵의 역할을 하게 되는 거구요
이제 두번째 및 유스 부분이 이쪽 워커는 리듀스 역할을 하게 됩니다.
실제로 그래서 이 그림과 같은 경우 이 논문과 같은 경우 구글에서 실제로
매니 주스에 대한 그런 공식 논문에서 제가 발치를 해왔는데요 그래서
여러가지 데이터들이 실제로 현 실생활에 여러분들 시스템에 존재를 할
거고요
그런 것들을 이런걸 쪼개 가지고 분석을 하기 위해서는 다양한 뭐 워커 들
그리고 cpu 자원들이 필요하게 됩니다.
그래서 첫번째로 이런 여러 가지 뭐 여기서 그림에서 보시는 5가지에 대한
데이터들이
좀 워커 들을 통해 가지고 당연히 사용자의 회원 요청 프로그램이 있을
거구요
나는 어떤것을 분석을 하겠다 라고 하면은 이 기존에 있는 정보 자체를
잘게 쪼개서 혹은 여러 곳에서 한번에 같이 읽어서 2
이제 맵을 하게 됩니다. 실제로 쪼갠다 라고 말씀을 드릴 수가 있을 것
같고요 그래서 이러한 데이터들을 쪼갠 다음에 그 나중 작업 리즈 에서
실제로 이 카운팅 을 한다.거나 혹은 이유 개수를 세는 하거나 혹은 이거에
대해서 특정한 패턴을 찾아 된다거나 하는 작업들이 리듀스 에서 일어나서
결과 깍두기 나오는 부분은 제 9 타일로 해가지고 여러분들이 원하는
포맷에 맞춰서 나오게 됩니다.
이게 기본적인 맵리듀스 의 분석 방법이구요 그래서
aws 에서는 그 이해 말을 통해서 실제로 이 하드 클러스터를 구성을
하기에는 여러분들이
이제 어떤 데이터를 뽑아 내겠다 사시는 유저 프로그램
이런 것들이 매우 중요한데 실제로는 하여도 클러스터를 구성을 하려다 보면
은 이런
주스에 대한 것들을 클러스터를 또 묶어 줘야 되기 때문에 운영에
대한 부분이 들어갈 수밖에 없습니다. 하지만 aws 에서는 예 말을
통한다.면 은 이 부분에서는
이에 말에서 지원을 해준다 라고 보실수가 있습니다.
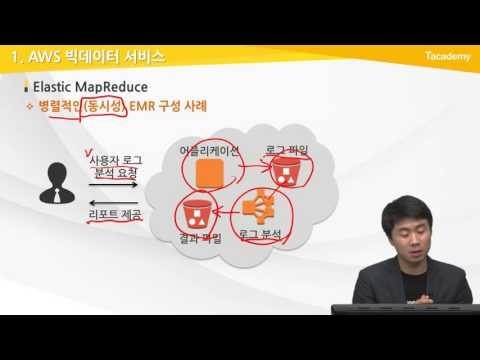
그래서 실제로 구성 사례에 대해서 조금 말씀드리면 은
병렬적 인 특히 혹은 동시성 이 있는 1나 스틱 메뉴 주스를 통한
여러분들이 서비스 구성을 한다. 라고 봤을 때
동시 성 이라고 말하는 건 이제 병렬 성 이라고 말할 수도 있는데요 동
시간에
이거를 요청 이온은 동시에
예를 들어 분석을 하고 거에 대해서 비즈 니스 넥스트 비즈니스에 대한
결과 까봐 룡 용도로 뽑아낼 수 있다
이런 것들을 멀티 스레딩 형태로 여러분들이 작업을 하실 수가 있다 작업을
하면서 예전 같은 경우는 그런 것들은 프라미스 환경이라면 은 한 서버에서
이런것들을 다 수행을 해야 되기 때문에 이 작업이 끝나고 이 작업을 해야
되고 그 작업이 끝나면 그 다음 작업을 해야 되고 이렇게 스케줄링 에
대한 부분을 여러분들이 신경을 쓰셨어요 되는데
aws 에서는 이런 동시성 클라우드 프로바이더 들은 이제 동시성 병렬
성을 제공하기 때문에 이에 말을 통해서 실제로 사용자 분석 로 9 요청을
하게 된다면 은 여러분들이 어플리케이션이 떠서 서비스가 지금 되고 있을
거구요 서비스가 되고 있는 와중에 분석 요청이 들어온 거고 그에 대해서
요구 분석을 할 수 있는 엘라스틱 맵리듀스 가 클러스터가 생성이 되구요.
생성이 되며 는 실제로 지금 쌓여있는 어플리케이션에서 계속 365일
24시간 로그를 쌀 건데
그리고 파일이 있는 에 스트립 s3 버켓 같은 곳을
라식 및 루스가 보고 여기에 있는 데이터를 가지고
결과값을 로 그 정보로 데이터의 에이 그냥 날 데이터 또한 데이터를
가지고 있는 s 리버티 에 대해서 여러분들이 실제로 활용 가능한 결과
파일로 뽑아낼 수 있게끔 라 스틱맨 믿을 스가 로그 분석을 해 준다 라고
볼 수 있습니다. 그러면 은 여러분들이 안에 어드민 이 라면은 리포트를
제공을 받을 수도 있구요.
혹은 사용자라면 은 이거에 대한 마케팅에 용도로 쓸 수도 있습니다.
그래서 이렇게 1나 승 맨밑 유쓰 를 동시성 있게 병렬적으로 구성을
한다.면 은 여러분들의 서비스가 서비스의 기능이 보다 많은 기능을 가져갈
수가 있고요
여러분들의 서비스의 부품 품질로 직결될 수 가 있습니다.
4 두번째 aws 분석 서비스에 대해서 말씀드리도록 하겠습니다.
앞에서 말씀드린 빅데이터 서비스 와 사시는 분석 서비스와는 비슷한 성격을
가지고 있는 서비스 따라고 볼수가 있구요.
하지만 저희가 분석서비스 라고 말하는 것들 중에서는
5 실시간으로 분석을 할 수 있는 키의 씨스 가 있을 거구요 못 위에
설명 드리겠지만 머신 로닌 이라던가 혹은 다른 분석 시스템이 aw 존재를
하고 있습니다.
첫번째로 이제 킹의 씨스 에 대해서 먼저 말씀을 드리도록 하겠습니다.
aws 에서 앞에서 말씀드린 1나 스윙맨 및 유쓰 같은 경우는 실제로
정적인 데이터에 지금 실시간으로 들어오는 데이터를 분석 을 하는게
적합하지 는 않구요 할 순 있지만 그것보다는
지금 쌓여 있는 데이터를 어떻게 효율적으로
정보로 뽑아낼 건지 가 좀 초점이 맞춰져 있는 서비스 였다면 은 키
네시스 같은 경우는 실시간 스트리밍 데이터를 손쉽게 로드하고 분석 처리할
수 있게 해주는 플랫폼 이다 라고 말씀드릴 수가 있습니다.
그래서 지금 실제로 들어오는 데이터를 데이터 스트링 같은 것들을 데이터를
실제로 키 네시스 에서 받아서
예를 들면 은 웹 사이트 클릭 스트림
그 다음에 금융거래 괌의 소셜미디어 피드 그 다음에 로브 혹은 위치추적
이벤트 같은 다양한 시스템에서 실시간으로 일어나는 데이터들이 많이 있는데
그런 것들을 지속적으로 데이터를 캡처하고 저장 가능하고 그리고 이것 또한
모니터링 그리고 대시보드를 통해서 혹은 sdk 라이브러리를 통해서
여러분들이 원하는 데이터를 실시간 데이터를 뽑아 낼 수 있는 서비스
다라고 보실수가 있습니다.
그래서 킹의 씨스 같은 경우는 실시간 데이터 분석의 적합하고 요 그
다음에 로브 데이터 수집 및 처리 에 적합하고 요 그 다음에 실시간 계층
및 앱 포팅 에 적합하다 라고 볼 수 있습니다.
그래서 키 네시스 에 대해서 실시간 분석 스트링에 대한 서비스의 구성
요소에 대해서 간략하게 말씀 드리도록 하겠습니다.
첫번째로 스트림 이라고 하는 실시간 데이터를 수영하는 1개의 샤드 라고
말을 하는데 이 4대가 우리가 실시에 7 생활에서 쉽게 생각을 했을 때는
하나의 큰채팅방 데이터를 모을 수 있는 하나의 큰 방 이라고 볼 수
있습니다.
그래서 이 하나의 샤드 는 2매가 바이퍼 세컨드 혹은 1 메가바이트 퍼
2nd 등 용량을 제공하고 있습니다. 그래서 여러분들의 시승한 데이터가 2
용량 이상으로 증가를 하고 2 용량 이상으로 데이터가 수집이 되거나 혹은
믿거나 하는 작업이라고 봤을 때는
이하 차드 자체를 모두 개 혹은 뭐 몇 개 혼 10개 까지
사실은 무제한으로 누릴 수는 없구요 aw 애써 제공하는 그런 콰 타
정책에 따라서 여러분들이 사들을 늘리고 줄이고
동쪽으로 하실수가 있습니다. 두번째로 빠 이오스 라고 하는 실시간으로
들어오는 데이터를
나는 저장을 바로 하고 싶다 s3 라던가 초에 bi 분석을 위한 레드
시프트 저장을 하고 싶다 라고 했을때 바이오스를 쓸 수가 있구요.
그리고 아직은 나오지 않았지만 분석에 대한 부분 셀 앞에서 말씀드렸던
emr 같은 경우는 스트레스 s 보다는 보다 정적인 분석
기존의 쌓였던 데이터를 분석하는 용도 라고 말씀드렸는데 키 네시스 에서도
앞으로 나올 분석 할 수 있는 서비스를 통해서 실시간으로 sql 라이크
1 커맨드를 통해 가지고 간편하게 분석을 시킬 수 있다라고 볼 수
있습니다.
그래서 처음에
앞에서 말씀 드렸는데 이런 다양한 데이터가 소 결합이 되기 위해서는
이렇게 우체통 어 싱크로 온 라이스 1
비동기 0 지금 상태의 경우에 데이터가 이렇게 메세지 들이 들어 오게
되고요
제 우편함에 인편 암 자체가 하나의 리차드 라고 말씀드릴 수가 있습니다.
그 4대의 용량은 이 문양을 가지고 있다 라고 말씀 드렸구요
그래서 이 쪼개 데이터가 메세지 드린 유입이 되게 되면 은 이 저희가 뭐
sdk 라던가 다양한 라이브러리를 통해서 나는 파란색의 매 쓰지만
믿고 싶다 라고 할 수도 있고 파란색의 녹색의
이 애쓰지만 뭐 카운팅 을 하고 싶다 라고 할 수도 있고 이 안에 있는
것들을 어떻게 분석을 해서 실제로 정보로만 뽑아 내고 싶다 라고 하실수도
있습니다.
혹은 이런 것들을 살 그냥 저장을 하고 싶다 라고 할 수도 있구요.
그래서 이렇게 키 네시스 에서 다양한 기능을 통해 가지고
저희가 원하는 서비스를 만들 수가 있습니다.
에 분석 서비스 중에서 두번째 뭐 심 논의에 대한 서비스 에 대해서
말씀드리도록 하겠습니다.
최근 들어 다양한 데이터들을 분석을 해야 되고 기 학습을 통해서 효과적인
데이터를 뽑아 낼 수 있게끔 많이 시스템을 설계를 하시는데요
실제로 머신 러닝 aws 머신 러닝 서비스를 통해서 여러분들이
복잡한 기계 약 알고리즘과 기술들을 쉽게 사용할 수 있는 하나의 서비스
다 라고 볼 수 있습니다.
실제로 aws 해서 5 기존의 아마존닷컴에서 쌓여있던 머신 러닝 노하우를
통해서 다양한 알고리즘 모델을 제공을 하고요
특히 aws 에서 머신 러닝 클러스터를 운영을 해 주기 때문에 서비스의
확장성이 높고 그리고 뭐 여러가지 확장성이 높은 2
5 수십억 개의 예측이 가능 하고요 그리고 이런 높은 처리량 과 함께
실시간으로 제공을 하고 있습니다.
그래서 머신 러닝에 적합한 기능이라고 볼 수 있는 것은
거래 데이터의 의심이 되는 부분이 라던가 혹은 상품주문 양의 예측
이라던가 혹은 콘텐츠 이 다양한 데이터를 가지고 고객에게 어떻게 큐레이션
할건지 개인화를 해 줄 건지 이런것들 추천에 대한 부분도 있을 거구요
그 다음에 패턴에 대한 예측 부분이라고 볼 수가 있습니다.
그래서 앞에서 말씀드렸던 5일날 쓰면 리지스 같은 경우는 지금 있는
데이터를 어떻게 잘 쓸지 에 대한 부분이었다 라고 말씀 드렸는데요
머신 넌 님같은 경우는 기존의 데이터를 가지고
미래에 나올 것들을 어떻게 예측을 할 건지 가 보다 적합하다고 볼 수
있습니다.
4 aws 에서 제공하는 머신 노 님의 모델에 대한 3가지 모델이
있는데요 이 3가지 모델에 대해서 말씀드리도록 하겠습니다.
첫번째는 이제 2분법적인 분류 모델
앞으로 나올 결과가 둘중에 하나 할 것 같은데 s 호 군도 몸은 a
아니면 p1 거 같은데 이 결과를 예측하는 게 2분법적인 모델이라고 볼
수가 있구요.
사실은 결과가 여러 개가 될 수도 있어요
그래서 다수 개 혹은 두 개 이상의 결과가 나오는 것들을 예측을 좀 하고
싶다 라고 했을 때는 다 문법적인 분류 분들이 적합하지 읽었구요
그 다음에 회귀 모델 실제로 상관관계 라고도 많이 표현을 하는데 기존의
예전에 a 라는게 나왔을 때 뭐 b 와 c 가 같이 따라 나왔다 이런 상
막는게 가 있었다 라는 게 데이터에 보이며 는 그 상관관계가 를 따져서
예를 들면 미래의 나오는 a 다시 가 나올 건데 a 다시 가 나왔을 때
피다 시와 시 다시 도 같이 나올 수가 있는 확률이 있다
이런 산간 이 있다라는 예측이 회귀 모델 이라고 보실수가 있습니다.
그래서 실제로 머신 러닝 의 분석을 통해서 다양한 것들을 여러분들이 측을
하실 수가 있구요.
새로이 아래에 있는 그림 같은 경우는 워싱턴에 있는 사정 거 셰어링 에
대한 프로그램을 통한 데이터에 머신 로닌 분석 인데 이거 같은 경우
캐쥬얼한 회원가입을 구제 하지 않고 사용을 했던 사용자들 같으면 관광객이
많았다 라고 저희가 볼 수가 있고요 그 다음에 등 놓고 를 하고 쓰는
사용자들 같은 경우는 출퇴근 시간에 많이 카운트가 올라가는 걸 보니 이
사람들은 여기서 국무 아는 사람들이다 라고 보실수가 있습니다. 그런데 이런
데이터를 가지고 여러분들이 추위에 마케팅 용도로 충분히 활용을 하실 수도
있을 것 같습니다.
네 그래서 aws 에서 이런 키 네시스 와 머신 러닝 을 통해 가지고
병렬적 인 그리고 동시성 있는 구성 사례에 대해서 말씀드리도록 하겠습니다.
실제로 사용자 트래픽이 지금 유입이 된다 서비스 유비 된다고 했을때 클릭
스트림
만약에 여러분들이 그 온라인 2 커머스 사이트를 구축 을 하고 있다
쇼핑몰 사이트를 구축 을 한다. 라고 했을 때는 사용자 트래픽이 들어오는
것들을 클릭에 대한 부분을
키 매시 스에서 좀 동시에 수칙을 할 수가 있구요.
그거를 추후에 이제 이에 말을 통해서 로그분석 또 당연히 가능할 거 고요
그 다음에 이런 것들은 실제로 사용자에 대한 흐름 자체를 머신 러닝 을
통해서 앞으로 사용되 이 패턴이 사용자들 그리고 각각 이 사용자가 어떤
패턴을 가지고 있는지를 머신 러닝 을 통해서 예측을 할 수가 있구요.
그거에 대한 추천 결과를 5 20초 라던가 혹은 s3 로 조장을 할 수가
있을 것 같고요
여기선 s3 로 저장을 했고요 그래서 그걸 가지고 여러분들이
관리자 라면은 여러분들이 비즈니스의 있는 사람이라면 그걸 마케팅 캠페인
용도로 쓰실 수가 있다 라고 볼 수 있습니다.
4 세번째 aws 모바일 서비스에 대해서 알아보도록 하겠습니다.
현재 동시성 있고 병렬적으로 사용을 할수가 있는 모바일 서비스에 대해서
말씀드리도록 하겠습니다.
모바일 분석 이라는 서비스 인데요 실제로 신규 사용자 대에 기존 사용자의
비율이 라던가 앱 수익 이라던가 지금 사용자가 아직 얼마만큼 머물렀는데
지 혹은 뭐 이벤트와 같은 핵심 트랜드를 추적을 할 수가 있구요.
실제로 추적을 한 다음에 앱 사용량과 수익에 대한 것들을 측정 까지
해주는 서비스다 라고 볼 수 있습니다.
그래서 여러분들이 만약 aws 위에서 서비스를 설계 하신다 라고 했을 때
특히 모바일 서비스 같은 경우는 모바일 분석에 대한 것도 aws 에서
제공해 주고 있구요.
많이 쓰시는 구글 어 널려 특수 랑 비슷한 서비스의 성격이라고 보실 수
있습니다.
그래서 이러한 데이터들을 실제로 여러분들의 s3 나 레드 시프트 추후에
이제 bi 비즈니스 인텔리전스 1 솔루션을 연동해서 비즈니스를 확장을
시킬 수 있는 그런 레드 시프트를 혹은 sd 에 저장해서 커스텀 분석도
가능하시고요 그 다음에 이런 대시보드
웹 aws 콘솔이 라던가 a 폐를 통해서 핵심적인 지표를 확인 가능하고
그리고 이걸 온 것들을 aws 에서 저장을 해 주고 분석을 할 수 있게끔
이런 서비스를 제공해 주기 때문에 비용 혈 적이다 라고 보실 수 있습니다.
모바일 분석에 대한 분석 지표의 대해서 간단하게 말씀 드리도록 하겠습니다.
여러가지 분석 지표가 있는데 첫 번째로 액티브 유저 에 대한 분석시 표
특히 오늘 하루의 많이 들어온 오늘 하루의 들어온 유저 갯수 혹은 세션
개수 에 대한 부분을 여러분들이 지표로 보실수가 있구요.
그 다음에 먼슬리 그 다음에 새로운 유적
그 다음에 특정 날 유저 중에서 월별 유저 사용량 득
이런것들을 확인하실 수 있습니다. 그 두번째 세션의
실제로 지금 여러분들이 구성 하신 어플리케이션의 토탈 3 써니 라던가
혹은 데일리 액티브 유저 세션에 대한 것들과 비교해서 에버리지 를 뽑아
낸다거나 이런 것들이 세션 탭에서 가능하시구요
그 다음에 레빈 u 비용 분석에 대한 지표 여러분들이
액티브 사용자들 중에서 먼 쓸 액티브 유저 중에서 실제로 과거를 1 at
미주 저는 몇 명인지 이런 것들이 확인 가능하시구요
그 다음에 다시 재구매 하는 비율
예 이번 오늘 혹은 위클리 외에 대한 비 텐션 들 제 구매에 대한 제
방문에 대한 부분에 퍼센트 ag 라던가 카운트를 하실 수가 있구요.
그 다음에 커스텀 이벤트 여러분들이 여러가지의 커스텀을 통해 커스텀
데이터를 보여 여기서 빌트인 해서 뭔가 확인하고 싶다 라고 했을 때 혹은
라이프 타임 이벤트 같은 것들
3 점 별로 이런 것들을 분석을 하실 수가 있습니다.
예 그리고 병렬 성분 식성을 가지고 있는 모바일 서비스 중에서 디바이스
팜 이라는 서비스가 있습니다.
실제로 안드로이드나 ios 플랫폼 기반의 스마트폰 태블릿에서 여러분들이
검증 취해 검증 같은거 테스트 같은걸 하셔야 되는데 이런 것들을 잘 할
수가 있게 끔 여러가지 테스트 베드를 마련해놓고 여러분들의 소스코드를
침체로 다양한 디바이스에서 확인하실 수 있게끔 병렬적으로 제공하는 서비스
다라고 보실수가 있습니다.
그래서 어플리케이션 테스트와 상호작용을 확인할 수 있게 해주는 앱 테스팅
서비스다 라고 보실수가 있구요.
그래서 새롬 디바이스 팜에 들어가면 은 수백가지의
안드로이드 혹은 ios 에 대한 디바이스 가 존재하고 요
그 외에 대해서 여러분들이 여러분들 애플리케이션이 ed 바이스 혹은 다른
디바이스에서 정상 쪽으로 동장 하는지를 병렬적으로 이 디바이스 팜 을
통해 낮이고 확인을 하실수가 있고 그리고 테스팅을 하실수가 있습니다.
이런 것들을 통해서 여러분들이 실시간으로 수백가지 가 되는 디바이스에
대한 상호작용을 확인을 하실 수가 있구요.
특히 개발 단계에 취해 이 단계에서는
이병렬 성을 가지고 서비스 타임 투 마켓을 하는 시간을 줄일 수 있다
라고 말씀드릴 수 있습니다.
이번 시간에는 동시성 있는 구현 혹은 방열 성이 있는 구성 방법에 대해서
살펴보았습니다.
첫번째로 빅데이터 서비스
특히 1나 스틱맨 뉴스를 통해서 대량의 데이터를 쉽고 빠르고 비용
효율적으로 배포하고 관리하고 처리 하실 수가 있고요
이런 것들을 aws 에서 관리 형 하드 프레임워크를 제공해 준다 라고
말씀 드렸습니다.
이런 것들을 통해서 여러분들이 기존의 쌓여있던 데이터들을
정보화 시켜서 여러분들이 서비스 기능을 보다 다양화 시킬 수가 있으십니다
두번째 분석서비스 키 네시스 를 통해서 실시간으로 들어오는 스트림에 대한
처리를 하실 수가 있고요
그것들을 분석 또한 하실 수가 있구요. 조장 또한 하실수가 있습니다.
그리고 머신 러닝 을 통해서 예를 들면 은 여러분들의 서비스의 예측을
하게 된다면 은 여러분들 서비스 구성에 품질을 향상 지킬 수가 있습니다.
4 세 번째 모바일 서비스
여러분의 어플리케이션 개발하고 테스트를 할때 다양한 기기들에 대한 상호
작용의 라던가 q&a 가 필요한데 디바이스 팜 을 통해서 병렬적 인
테스트를 수행 가능 하시고요
그 다음에 여러분들이 런칭을 한 이후에 서비스 중인 데이터들을
모바일 분석을 통해서 다양한 서비스를 분석 유저 라던가 세션 들을 분석을
할 수가 있다 라고 말씀드렸습니다.
댓글 0개
등록된 댓글이 없습니다.